MultiGenera
English version
Versión en galego
Generación multilingüe de estructuras argumentales del sustantivo y automatización de extracción de datos sintáctico-semánticos
MultiGenera es un proyecto de investigación financiado por la Fundación BBVA, que tiene como objetivo diseñar un prototipo para generar automáticamente frases nominales en español, alemán y francés. La herramienta MultiGenera posibilita, por tanto, la generación automática de realizaciones argumentales nominales dotadas de información semántica.
Este simulador multilingüe bebe de las fuentes de la gramática y lexicografía valencial (Engel, Mel’čuk, etc.) y de los trabajos sobre ontologías para redes semánticas como WordNet y sobre otros recursos de Procesamiento de Lenguaje Natural (PLN), lo cual permitirá un análisis onomasiológico-conceptual de diferentes campos léxico-conceptuales de modo monolingüe e interlingüístico y una aproximación comparativa y contrastiva a los sustantivos representantes de diferentes campos léxico-conceptuales.
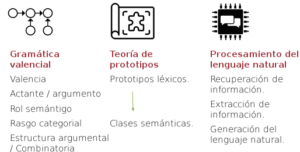
Para el desarrollo del multigenerador ha sido necesario desarrollar un método combinado para la recogida y análisis de datos sobre la combinatoria sintagmática y paradigmática del nombre:
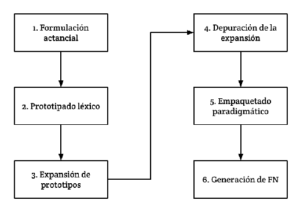
Dicho método se basa, en definitiva, en la extracción automática de datos desde recursos PLN, en el análisis de corpora, bases de datos de coocurrencias, Wordnets y en la evaluación de datos que arrojará el propio multigenerador MultiGenera para el español, alemán y francés.
Los resultados de este proyecto se concretan en el estudio de la viabilidad del prototipo del simulador atendiendo a la combinación de métodos y a la interoperabilidad de recursos así como al desarrollo de la propia herramienta MultiGenera.

Como citar:
Domínguez Vázquez, María José (2021): “Zur Darstellung eines mehrstufigen Prototypbegriffs in der multilingualen automatischen Sprachgenerierung: vom Korpus über word embeddings bis zum automatischen Wörterbuch”, en Lexikos 31, 20-50.
Domínguez Vázquez, María José & Solla Portela, Miguel Anxo & Valcárcel Riveiro, Carlos (2019): Resources interoperability: exploiting lexicographic data to automatically generate dictionary examples. Electronic lexicography in the 21st century. Proceedings of the eLex 2019 conference. 1-3 October 2019, Sintra, Portugal. Brno: Lexical Computing CZ, s.r.o., 51-71.
Domínguez Vázquez, María José & Valcárcel Riveiro, Carlos & Lindemann, David (2018): Multilingual Generation of Noun Valency Patterns for Extracting Syntactic-Semantical Knowledge from Corpora (MultiGenera). Proceedings of the XVIII EURALEX International Congress: Lexicography in Global Contexts, Ljubljana, Slovenia: Ljubljana University Press, 847-854.
")

